互動式對話編碼模型
技術授權與產學合作諮詢
2019-07-03
互動式對話編碼模型
本院覽號
05T-1071206
公告日期
2019-07-03
智財權狀態
know-how
摘要
過去有許多研究投入建模以分析對話文字內容,它們使用句子內容和前後脈絡來編碼對話句,並經常假設當前文字與鄰近文字具有相似性。然而這個潛在的假設並沒有考慮對話記錄或者線上聊天等對話獨有的特性。 每個人都有不同的心理狀態、文化及用語習慣,在本技術中,我們考慮每一個發言者的狀態對於對話資料的分析有關鍵性的影響,因而提出一個可以將對話中每一位發言者的每一句發言動態編碼的方法,來取得涵蓋對話者狀態的對話文字編碼,以進一步分析使用者的對話內容。 我們的編碼方法用在對話使用者的情感預測標準數據集上,比起目前效能最好的模型,尚能提高3%的正確率,使用在其他對話數據集如EmotionLines、 DailyDialog和Ubuntu Chat Emotion上,亦優於目前其他常見的方法。
技術優勢
- 我們提出兩個可以運用語句變換與使用者狀態變換來編碼文字對話的模型,並從中顯示出考慮此兩因子的有效性。
- 我們應用此對話編碼方式,提出了目前最先進的文字對話情感辨識模型。
應用範圍
- 對話產生
- 對話情感分析
- 對話探勘 (供後續其他預測,如使用者喜好等使用)
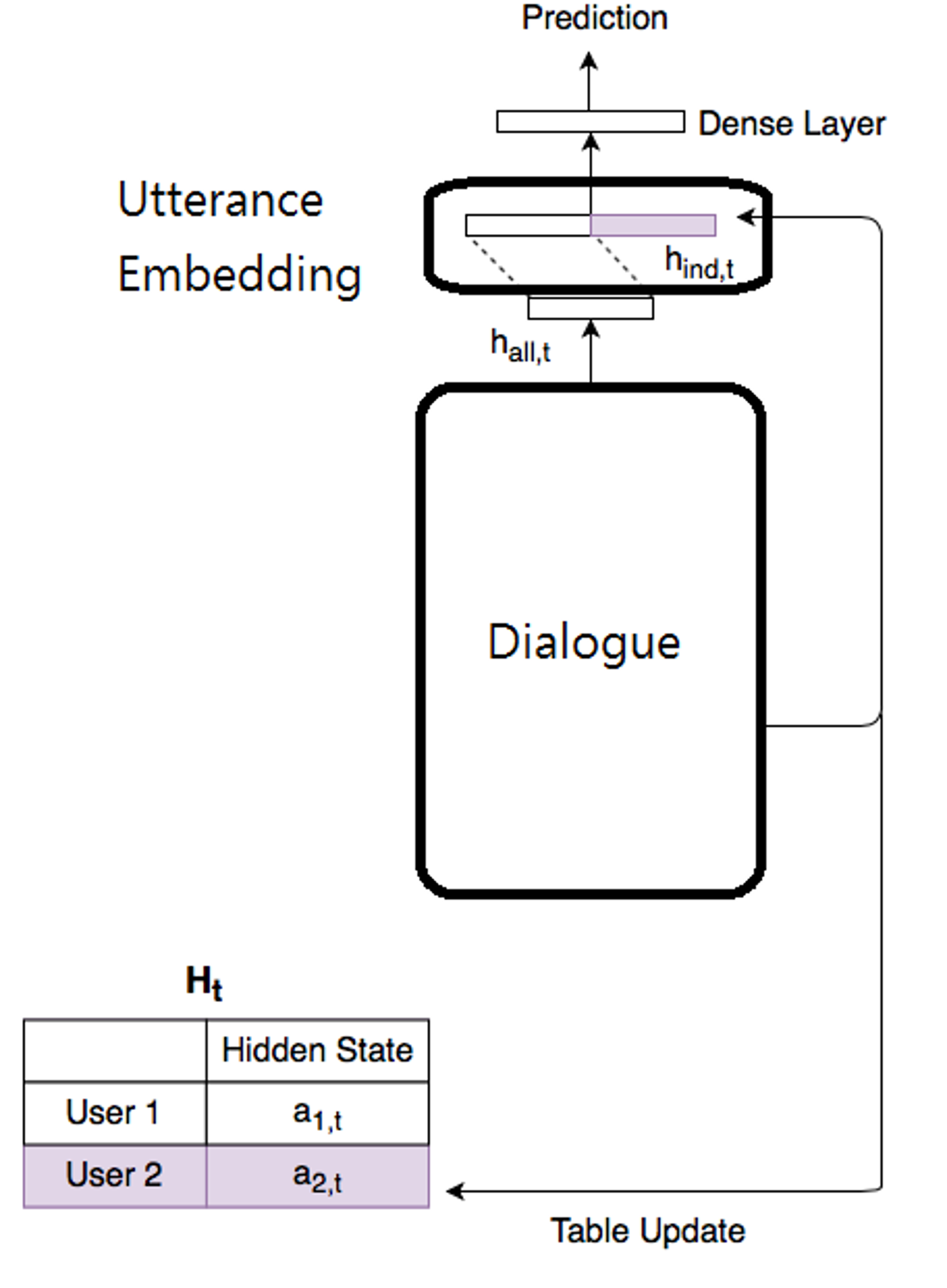
Dialogue Embedding Flowchart. The utterance embedding is the output of this technique.
創作人
古倫維
檔案下載
 互動式對話編碼模型
互動式對話編碼模型